Multi-task vision-language model supporting visual question answering, image captioning, object detection, and point localization.
Parameters
image_input
str | PIL.Image | np.ndarray
required
RGB image.
Task type: "vqa", "caption", "detect", or "point".
Text prompt/question. Required for vqa, detect, and point tasks.
Caption length: "short" or "normal". Only used for the caption task.
Maximum number of tokens to generate (default: 100).
Returns
dict with key "output" containing task-specific data:
- vqa / caption: Text string
- detect:
{"boxes": [[x1,y1,x2,y2], ...], "scores": [...], "labels": [...]}
- point:
{"points": [[x,y], ...]}
Example Output
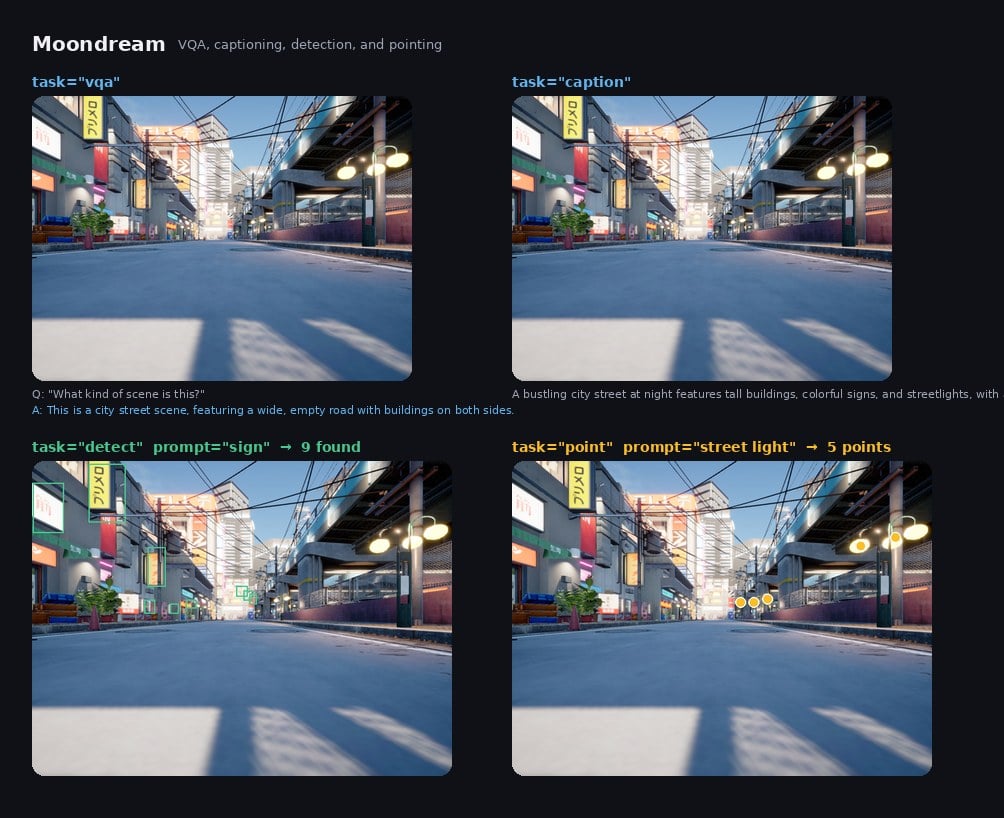
Example
from grid_cortex_client import CortexClient
import numpy as np
from PIL import Image
client = CortexClient()
image = np.array(Image.open("scene.jpg")) # 640x480 RGB
# Visual Question Answering
vqa = client.run(model_id="moondream", image_input=image, task="vqa",
prompt="What kind of scene is this?")
print(vqa["output"])
# "This is a city street scene, featuring a wide, empty road with
# buildings on both sides."
# Image Captioning
caption = client.run(model_id="moondream", image_input=image, task="caption", length="short")
print(caption["output"])
# "A bustling city street at night features tall buildings, colorful
# signs, and streetlights, with a train station and overpass in the
# distance."
# Object Detection
dets = client.run(model_id="moondream", image_input=image, task="detect",
prompt="sign")
print(len(dets["output"]["boxes"]))
# 9
print(dets["output"]["boxes"][:3])
# [[86.25, 4.22, 142.5, 93.28],
# [1.56, 33.05, 48.44, 109.45],
# [176.25, 131.25, 203.75, 191.25]]
# Pointing
points = client.run(model_id="moondream", image_input=image, task="point",
prompt="street light")
print(points["output"]["points"][:3])
# [[584.375, 116.25], [589.375, 121.41], [531.875, 129.375]]